I applaud Anthony Albanese’s statement yesterday that Australia will not allow AI to be trained on artist’s works without
their permission. In a major speech he said:
Australian writers, musicians, artists and journalists must retain ownership and control of their work. Our laws will
spell that out, plain as day. An artist’s creative endeavour is their work and their property. No company should use
Australian books, music, art or news to build or train AI without the artist’s control. That includes the artist’s
control of the price and value of their work. Anything less is theft.
However there wasn’t any concrete detail on how this would be enforced. It won’t be easy to enforce because we’re already
behind: almost all the AI in use today has been trained on copyrighted works without permission—theft, as the Prime Minster
puts it. That’s a problem because even if we respect artist’s work from now on, the existing AI models based on their
stolen work will still be around. As Albanese said:
No government can turn back the clock or press pause on all of this. Nor would we want to.
So what should we do about AI that has already stolen from us? I reckon we should take it back! I think the deal should
be that if you take our work for free, then we get the ensuing AI model back for free.
Ideally that would mean AI models trained on stolen works should lose copyright protections. We would be allowed to take
the AI models from Claude, Gemini, GPT, Grok, Muse, etc and run them ourselves on our own equipment without paying
anything to Anthropic, OpenAI, Google, etc. Of course I don’t expect that to actually happen because there would be a
mighty uproar if our government were to actually pursue that. The big tech firms would be outraged and the US government
might threaten Australia (the biggest AI firms are all American), despite the obvious irony of thieves outraged about theft.
But all that is unnecessary because someone is already taking AI back from big tech firms: the Chinese AI labs, who
are allegedly stealing American AI models on an industrial scale. The Chinese AI models such as
GLM, DeepSeek, MiniMax, etc are very good; nearly as good as top American AI models, and occasionally beating them.
Unlike most US tech firms, however, Chinese AI labs make their AI models available to download and use for free. So the
Chinese AI labs are already doing what I think all AI companies should do: giving their AI back to the public that they
took the data from.
Australian government could simply make it a requirement that government AI must use open-weight AI models, unless a
proprietary AI model has been trained without stolen work. Given that so few models are free of stolen work that
effectively means we would switch from proprietary American AI models to free Chinese AI models. This might sound scary
to a Sinophobe but it would actually improve Australia’s sovereignty because it reduces the leverage any foreign
government has over us. Right now the USA can take away our access to AI (as Trump did with Fable) or jack up prices,
but if we run open weight AI models ourselves then neither USA nor China can stop us or surveil us.
The result would be that we stop rewarding AI companies who have stolen our work, and give them an incentive to seek out
permission before training their next AI models. We render the upcoming laws to protect our artistic works meaningless
if we continue to pay money to companies for AI based on stolen works; now is the time to stop doing that.
Tonight the Australian Government announced that it is removing the current 50% discount on Capital Gains Tax (CGT),
and is introducing a minimum 30% tax on gains. Good. I think that everyone should pay a fair share of tax, and it is
unfair that people with investments get an unlimited discount on their taxes that wage earners don’t.
There has also been quite some disquiet from the tech industry about getting rid of this CGT discount. In particular,
Paul Bassat (co-founder of Seek and other startups) said that if the discount is abolished, “founders will leave
Australia in big numbers”.
So I’m posting this to say that I’m an Aussie startup founder, and I’m not leaving Australia.
The CGT discount is just not an important factor in my decisions as a founder and an investor. I have co-founded two
successful startups, SmartyGrants sold to Our Community and ThinkTilt sold to Atlassian, so I’ve benefited
from CGT discounts in the past. I can honestly say CGT had no impact on my decision to found those
startups or on where they were domiciled. I founded them because the products were needed, and Australia was the right
place to found them. It just doesn’t make any sense that I would move overseas to avoid a bit of extra tax five to ten
years from now at the cost of losing the ideal customers, staff, or partners for the business that we have here in Australia.
I reckon I can say the same for the people we’ve employed and the investors who trusted their money with us. I never
heard any of them talk about getting into startups for the CGT discount, it was always about believing in the product
and the team. Investing in startups is all about betting on which startup will grow exponentially, and if you really
believe that you’re on to a winner I highly doubt CGT is going to discourage you from investing. If you gotta pay a lot
of tax because the startup is successful… well, then that’s a good problem to have.
Of course I don’t speak for all founders, and perhaps some really will leave Australia because they think CGT discounts
are necessary to their success. If that is true then I think Bevan Slattery’s suggestion of keeping CGT discounts for
Australian residents investing in Australian startups is a great way to mitigate that. And even if it’s not
true I still think there’s some argument that keeping the discount for Australian startups would be fair and productive.
Australia has lost a lot to foreign big tech and we need to find ways to rebalance that. We’ve seen advertising money
sucked out of Australia’s economy from our media by foreign big tech like Alphabet (Google) and Meta (Facebook), taxi
fares sucked out overseas by Uber and DiDi, shopping revenues sucked out overseas by Amazon and Temu, etc, etc. It might
seem fair at face value that all investments are taxed the same, but is it really fair that a foreign monopoly which
shifts profits offshore is treated the same as a local startup bringing real competition?
But hey, that’s a question for the policy wonks and I’d rather focus on launching my third startup: Neighbo, the search
engine for Melbourne. None of this stuff changes my plans one bit. Neighbo is proudly founded—and staying—here
in Australia regardless of any tax system changes.
There are more important things to be said about Atlassian firing 10% of staff today, but I note a
concerning small detail: that AI seems to have been used to prepare Atlassian’s memo to staff.
AI should not have been used here.
I realise that there are a variety of opinions about AI and what it is appropriate for, and that some people think using
AI here is fine. We won’t all agree on what the right level of AI use is but hopefully we can all agree that the level
is neither never nor always. There are times when AI may be used, and times when it should not.
Then the question is what are the times when AI should not be used? I think that sacking people is one such time. I am
confident that Mike Cannon-Brookes genuinely cares about how Atlassian staff feel about the firings and wants to
communicate the reasons honestly and sincerely to staff. He, and his Chief of Staff Amy Glancey, and other good people
at Atlassian would surely have put in a lot of work and thought into the memo given to staff and the media. There is a
part of them in that memo.
And yet the memo comes across as having the shallow and generic style of AI writing. It has the stylistic AI tells of
unnecessarily short sentences, the three-item lists, the repetition (ironically on ‘decisiveness’), and the more
impersonal passive voice. It also has the formatting AI tells of boldfacing individual words, and increased em dash use.
If you don’t see these yourself then I suggest you read the memo from Atlassian’s first big round of firings
published on 6 March 2023. It says mostly the same things, and yet it feels so much more human than
the 2026 memo.
It matters that this memo feels like a machine generated it. Telling someone they are fired is one of the most human
things we can do in business. I’ve had to fire people and so I know how difficult and emotional it is; if I have to do
it then I want to show my staff that I take it seriously. I wouldn’t risk an AI having any involvement in the
process—not in the decision-making nor in the communication of the decision—because that feels cruel and inhuman.
And what do you get from running an AI over your writing? In the case of firing thousands of staff you’ve already spent
days or weeks fretting over what to say, so you’re saving precious little time by getting an AI to rewrite it. For that
negligible benefit you scrub the humanity from your writing at precisely the time when it is needed the most. That’s a
terrible tradeoff that no-one should take; I wouldn’t, Atlassian shouldn’t have.
For Atlassian I think it matters more than most. The tech industry is all-in on AI right now, investing historically
unprecedented amounts of money into AI, and Atlassian is trying to position itself as a major player there. Meanwhile
the general public is not buying it—in either sense of the word. The general sentiment towards AI is negative across a
range of surveys, and though there are some AI products which are popular there is also a notable reluctance from people
to actually pay for them. It’s clear that some AI products have value and a place in our future, but it’s not clear that
people are willing to pay enough money to cover the immense cost of all this AI investment.
If the AI industry is to avoid collapse it should acknowledge the reality that it is not entirely welcome. It should
show us that it understands and respects that AI can’t be used everywhere, focussing on doing the things we accept while
drawing strong red lines delineating where AI is simply unacceptable. There has been some recent debate over whether
Anthropic’s red lines of using AI for mass surveillance and fully autonomous weapons are appropriate, but in my opinion
those are way, way over the red lines that most people on this planet actually have. People don’t want to see AI replace
all art and music. People don’t want AI to have power over their health and safety. And people don’t want to be fired by
an AI. Atlassian and the wider tech industry should demonstrate that they understand AI must not be used everywhere, and
that includes steering clear of AI when firing staff.
AI is an important technology. It really can do things that were previously impossible.
However the vast majority of AI today is useless. A waste of time, money, and resources.
AI will eventually become useful, but it will take much longer than you think. Just like the Industrial Revolution couldn’t have happened without the social changes of the Enlightenment, it may take decades of social change before an AI revolution really happens.
AI is unable to replace people. AI might make us more productive (and cause job losses), but AI does not work autonomously. Only people can make a decisions; AI cannot because it takes no responsibility for its actions.
AGI (Artificial General Intelligence) could change the above, but is not imminent. Perhaps we’ll not see an AGI this century. Someone will surely claim to have an AGI soonish, but it will be a dud and our collective response will be “yeah, nah”.
I doubt this will change much in the next year. Let’s reconvene in 2027 and see if I was right or wrong.
Australia’s social media ban for under-16s starts today, and unlike many in the tech industry I’m in favour of it.
Not because it’s a good law. The law has a lot of problems: rushed, inconsistent, unproven, it risks privacy and
isolates kids and pushes them to less safe platforms. The law may be harmful, yet I’m still in favour of it.
Not because the reasons this law exists are honourable. Of course the parents who lost kids to suicide have honourable
intentions, but I’m not so sure about News Corp Australia and Nova Entertainment who campaigned heavily for this ban.
News Corp has long been losing advertising revenue to social media, and their campaign coincided with
Meta announcing it would no longer pay News Corp (and others) for news. Did they campaign because it is a
good cause, or because of the financial interest they have in turning people off social media? I don’t know, and yet I’m
still in favour of the law.
No, the reason I favour this bad law of questionable provenance is because social media platforms have failed their
basic responsibilities. Social media platforms have prioritised maximising engagement over everything else,
promoting division, spreading lies, damaging our social fabric, undermining democracy, damaging mental health,
and ignoring crimes spreading virally on their platforms. I have reported to Meta dozens of scams and breaches of
rules that I’ve seen on Facebook and Instagram, and almost all of my reports were closed with no action taken. Whether
or not their indifference is legal I consider it to be a failure of their basic responsibility to society. When
companies fail us so profoundly then government has to step in.
We have to halt this growing hubris from careless people at social media platforms.
Several platforms act like they can do anything they want; we need to shock them into a realisation that
they have gone too far. A ban on children probably isn’t enough to truly scare recalcitrant platforms, but it is
a watershed moment where they have lost their invulnerability and the momentum is against them.
My hope is that some social media platforms will recognise the significance of this shift and learn to be responsible
citizens. That’s because I reckon the tech industry is much more capable of fixing these problems than government is.
Social media platforms have plenty of money, lots of staff, better technical knowledge, the ability to move faster than
government, and of course access to the code and algorithms that make social media work. Governments are constrained in
their attention and budgets, and have a reputation for not regulating technology well.
The answer is not to mope about how the government never gets this stuff right. The answer is that the industry itself
has to get its shit together and do things properly, responsibly, and ethically. The industry has to be so good that
government doesn’t need to step in again. Bad laws are the fault of bad companies that fail to do things right.
Some platforms will not learn. We should shut down the ones that don’t. Sure it would cause an uproar if, say,
Facebook and Instagram went away. But just like Aussie kids are already finding new places to hang out online, we
adults would find alternatives too (those alternatives already exist but you haven’t looked for them). And though
Australia couldn’t force the USA or China to shut down a social media platform, banning Australian businesses from
using or advertising on a platform could be quite effective. Why couldn’t we sanction a misbehaving social media
platform just like we sanction thousands of entities that threaten Australia?
So ultimately I support this flawed law because it’s a step in the right direction. It might push some platforms into
more responsible behaviour. It will make it more politically palatable to completely ban irresponsible platforms one day.
Social media isn’t yet fixed, but the platforms are finally on notice.
I’m far too old to be kicked off social media by Australia’s social media ban that starts next week, but it could
happen to me anyway. The Social Media Minimum Age scheme which starts on 10 December 2025 obliges social media
platforms to take reasonable steps to prevent Australians under 16 from having accounts. That means some adults will
have to prove they’re over 16 to continue using social media.
If a platform asks me to prove my age I will choose not to do so; instead I’ll just stop using that platform.
That’s because I think it’s not worth risking my personal information being stolen and misused. The Social Media Minimum Age
act does contain privacy protections, but so too does the Privacy Act and that hasn’t worked. Personal information I
have given over the internet to Australian businesses has been stolen by criminals on at least seven occasions
already (specifically Canva, digiDirect, Latitude Financial Services, SitePoint, Ticketek, Qantas, and
Bunnings via FlexBooker). Legislation doesn’t stop hackers. In my opinion the best way to protect my personal
information is to not give it out unnecessarily.
As such I have routinely lied about my age online; that way when my information is stolen it can’t be used to open bank
accounts or trick government departments. On Facebook I’m over 100 years old! Problem now is that if Facebook asks me to
prove that I’m over 100 years old I will be unable to, because in reality I’m not even half that.
So I write this just in case I disappear from some platforms next week. I might not be on Facebook or Instagram, but
I’ll still be online so look for me elsewhere. Maybe I’ll start writing here on my blog more?
In recent weeks there has been a lot of talk about how Australia should use AI to increase productivity. I agree that AI
could help productivity, but I also reckon AI is a distraction. A lot of the productivity benefits will come from making
information and processes available online so that AI can use them, rather than from the AI directly. AI can’t push a
button or call an API that doesn’t exist, so to make AI useful we’ll have to create those things—and we will benefit
from that whether or not we choose to use AI.
What I’m saying is that instead of rushing into an expensive and complex AI system to do things, why not start with a
simple button that does the thing instead?
Scott Farquhar, Chair of the Tech Council of Australia, has actually hinted at that in a less-noted part of his
recent National Press Club address (Disclaimer: Scott’s company Atlassian acquired my company ThinkTilt in 2021,
but we have no current connection). He’s very much in favour of adopting AI, but he also asks for all levels of
governments to make their services available via an API. I agree. APIs are how we make information and processes
available online, and I think both business and government should focus on adopting APIs before AI.
Some specific examples:
I signed up for a Zinzino oil subscription online, but later discovered their website doesn’t provide a way to cancel.
I had to contact customer support and ask them to cancel my subscription. An AI chatbot could be set up to handle that
instead of a human customer support agent, but really a cancel button is all I needed.
Every three months I spend a few minutes manually paying my rates to Merri-bek City Council. I’d rather that be paid
automatically from my bank account, but that requires me to fill out and sign a paper form so I haven’t bothered. I
don’t need an AI agent to handle this for me, all I need is an online form with a button to submit it.
My Mac computer is regularly crashing with an MD_UNCORR_ERR error. I tried asking AI for help but it wasted my time
with hallucinations. For AI to be helpful here it would need access to internal Apple documentation, but if we could
access internal Apple documentation then all I would need is a search button rather than an AI.
Scott Farquhar gave an example in his speech of an AI virtual agent offering him a replacement for a faulty product.
Sure an AI agent can do that, but a single button to order a replacement would have been simpler and faster.
None of this is to say that AI won’t have any benefits. Scott’s example of AI skin cancer screening is a good example
of something that can be done better with AI (after all, your body doesn’t have APIs). But in many popular examples of
how AI might revolutionise our lives the AI seems dispensable—the real revolution would be that business and government
open up their processes and information. They don’t need an expensive and complex AI solution to do that, a simple
button would suffice.
I’m pretty sure that stealing all the books and research papers from the US nuclear weapons programme would be illegal.
I’m also confident that giving those books to, say, Iran would break a whole raft of other laws too.
What if instead you used the stolen books to train an AI model, transforming the books into an LLM which doesn’t
contain those original sources verbatim? Surely still illegal to give to Iran because nuclear secrets can be gleaned
from the LLM. However what if transformation is so extreme—the LLMs parameters so small—that all the nuclear secrets
drop out leaving (probably) only basic physics knowledge which isn’t illegal to distribute?
It’s a moot point. I’m sure the US authorities would lock you up for stealing the books, and you’re not going to be
allowed to distribute the LLM.
That’s not what happened in this week’s US court victory for Anthropic. The judgement found that transforming books
into an LLM was fair use, but that stealing books was not—so only the stealing part can be taken to trial. Anthropic’s
LLM was not immediately shut down.
If instead the books had been stolen from the US nuclear weapons programme rather than from Libgen and PiLiMi it surely
would have been shut down immediately. Obviously that’s because stealing nuclear secrets is a more serious crime than
stealing copyrighted books, but they’re both illegal. Anthropic hasn’t yet been convicted of stealing books so it is
reasonable to wait to take action, but that’s a delay not an abandonment.
A trial on Anthropic’s stealing of books could—and in my opinion should—order that Anthropic’s LLMs get shut down.
Not just Anthropic; journalists report it is likely that all major LLMs are trained on stolen books. It is possible that
in time all major LLMs get shut down by the courts.
The industry should be responding now by training LLMs legally, not waiting for the law to catch up. I’d like to start
using AI but I don’t want to be handling stolen goods.
However I do not blame the government for this misguided law, I put the blame squarely on the big social media
platforms. Tech companies should have dealt with the problems their platforms are causing, but instead it
feels like they have been shirking their responsibilities. Australians are overwhelmingly angry with them:
77% want kids banned and 87% want greater penalties on social media companies that do not comply with Australian laws.
The government was clearly pressured to step in and do something, anything. The result is a law that is bad for those
platforms, a law that they could and should have prevented.
I’ll give you a personal anecdote about how Facebook has failed me. This is something I reckon Facebook should have
solved, and their lack of action has made it inevitable the government would step in.
My Facebook feed is flooded with scam advertisements. There are often times when most advertising I see on Facebook is
for scams. They are the same scams that Facebook has been showing me for years and has failed to stop. Not only does
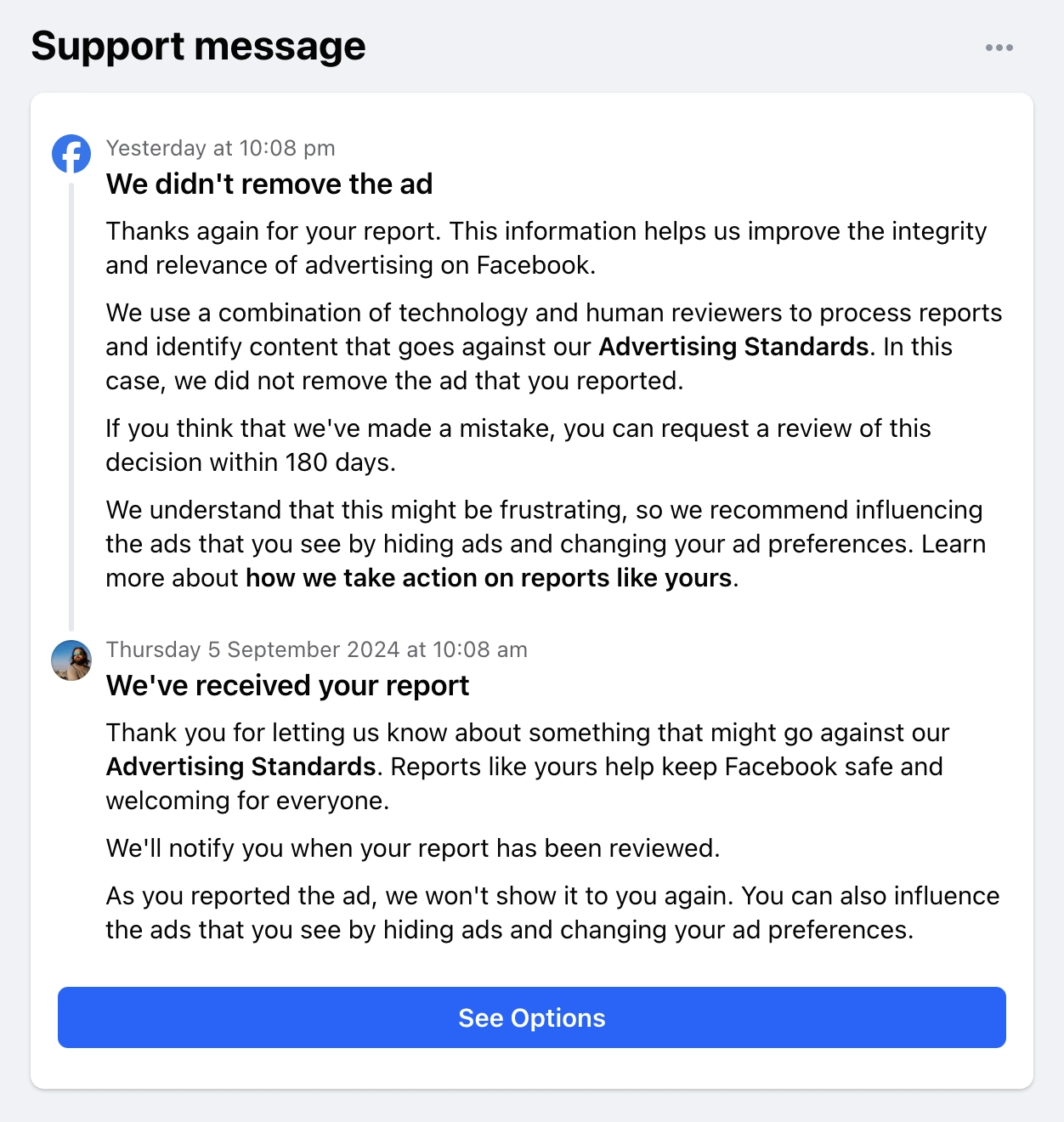
Facebook keep showing me those scams, but Facebook also routinely rejects my reports about them.
In my last blog post I wrote about on particular fake Paul Hogan scam ad which I reported to Facebook but they
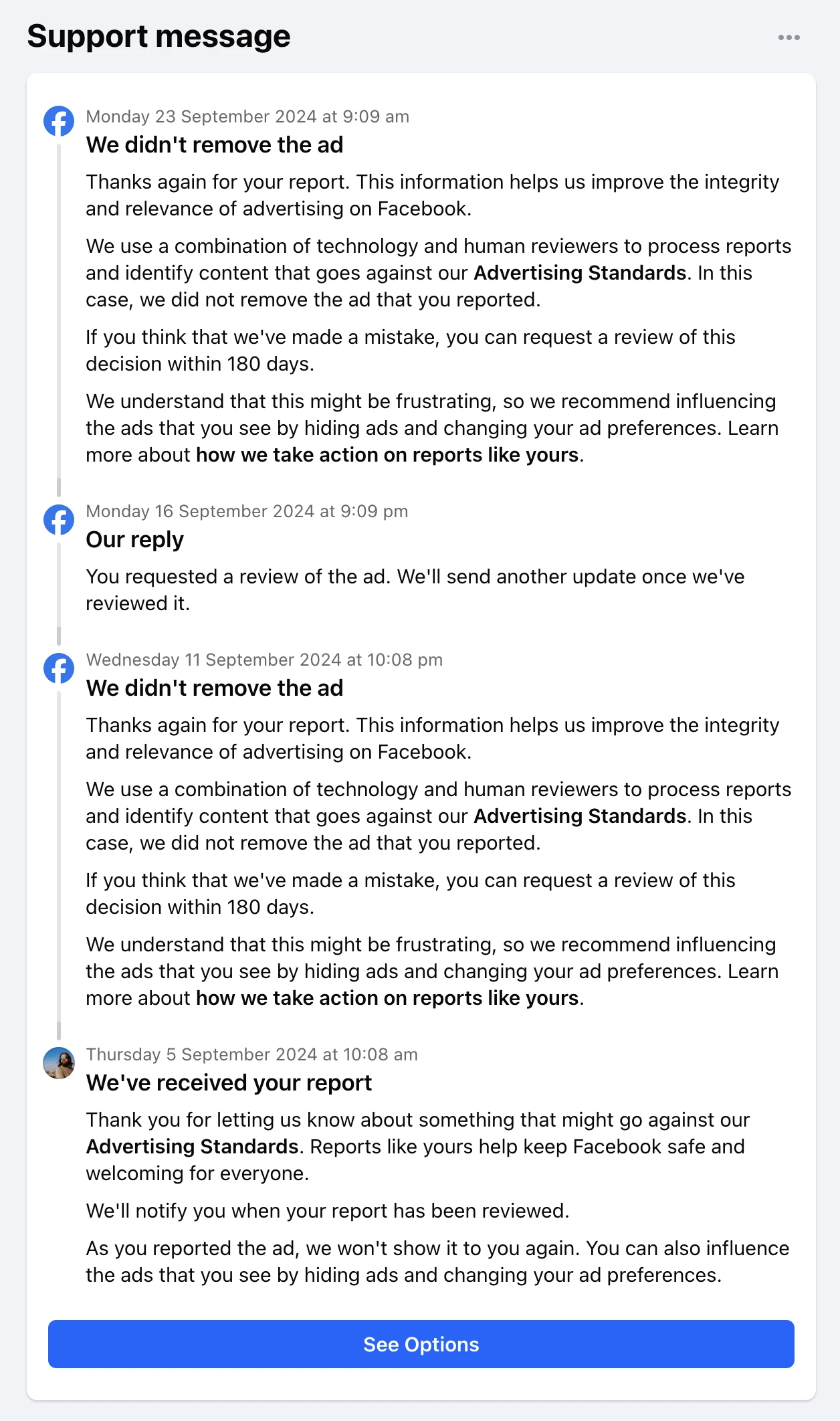
didn’t remove. Since then I escalated that report by requesting another review of the ad. The second review came back
and yet again Facebook did not remove that ad:
This is not an isolated incident. The last 30 scam ads that I’ve reported to Facebook have not been taken down. The last
time Facebook took action on a scam I reported was so long ago that Facebook has since deleted the message from my
Support Inbox.
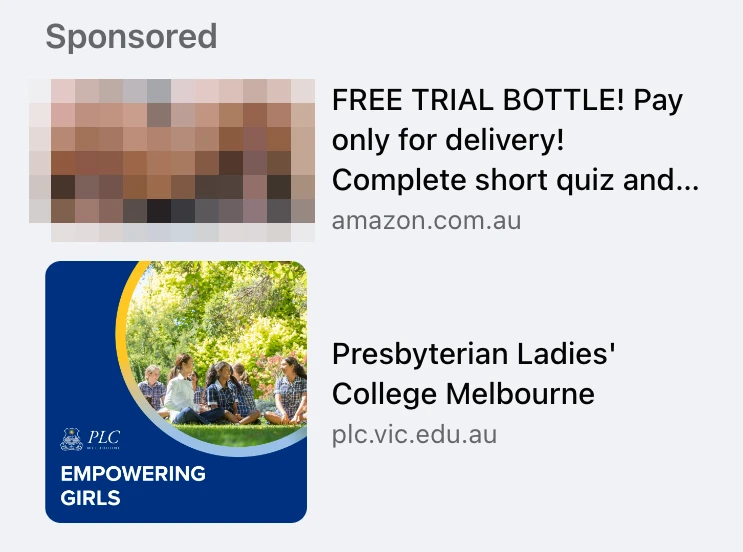
Sometimes instead of showing me scams Facebook shows me advertisements featuring hardcore pornography. Here’s an example
of one such ad, censored by me so that I am not distributing porn on my own website:
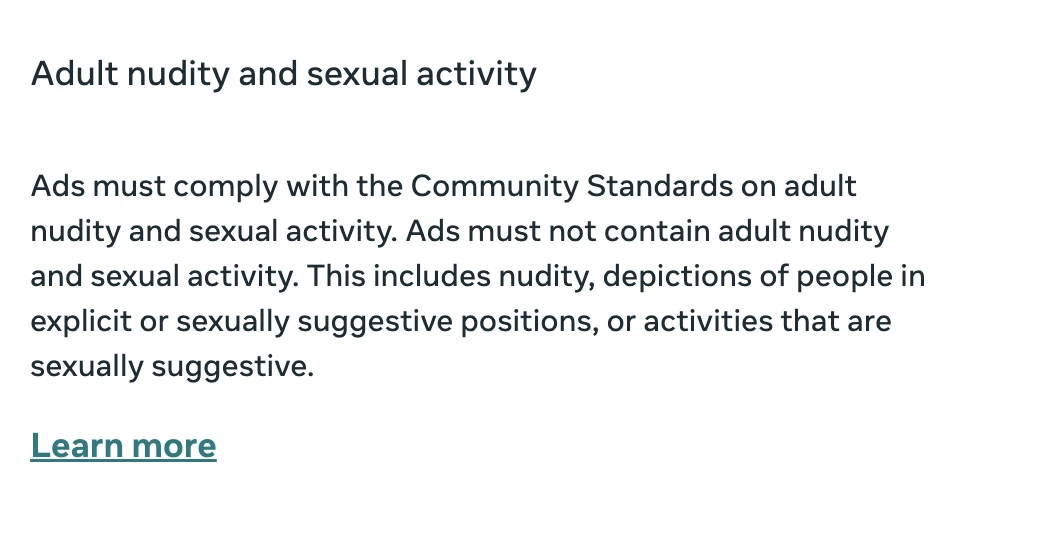
The advertisement that I have pixelated showed a man and woman having sex, with an erect penis and copious amounts of
semen. It was a clear breach of Facebook’s Advertising Standards, which have specific prohibitions on adult nudity and
sexual activity. Facebook displaying this pornographic ad was made even worse by the fact that they
placed it next to an ad for a private girl’s school.
I reported the ad to Facebook but they did not remove it:
Facebook has failed here.
I understand that occasionally things slip through the cracks, but Facebook should take action when such problems are
reported. Unfortunately Facebook routinely fails to take action when I report a scam. That is unacceptable to me,
and surely to most Australians as well.
What would be acceptable? I can’t speak for all Australians but I think a reasonable expectation is that Meta should
not allow scam ads or pornographic ads to appear on Facebook in the first place. I reckon Facebook could step up and
actually achieve that: simply have a person review each ad before it is published, looking for the obvious scams and
porn. Perhaps AI will be helpful to detect scams because Facebook is an AI leader, but if they’re using AI to
detect scams now it is clearly failing given the prevalence of scams. So I think Facebook really just needs a lot of
people to do the reviews. It would be expensive but surely that is better than alienating most of the population and
forcing government to ban social media?
Facebook scams are not the only problem on social media and not the main reason behind the government ban on social
media—just the one I encounter the most. But those scams are a reasonable illustration of the kinds of problem that
social media platforms should be making more of an effort to fix. If they don’t fix these things then the government
will… and probably badly.
btw. I will be taking my own advice on my new project neighbo.au. You can read about that on the Neighbo
blog.
Facebook has been showing me advertisements for investment scams for many years. When I report the scams to Facebook
they mostly reject my reports despite the ads being clear breaches of Facebook’s advertising standards. Their response
is typically “we didn’t remove the ad”.
Why? The scam ads should be easy to detect because the scams have been following the same pattern for years.
I’d expect Facebook to be able to use their AI technology to automatically detect the scams. Facebook and its parent
company Meta make some of the best AI technology and are spending billions on AI, but perhaps their
AI simply isn’t up to the task. Humans certainly are though; a person would notice the scam in seconds. So why doesn’t
Facebook notice the scam when I report it?
I suspect humans aren’t even looking at the reports I send in. I reckon they should be.
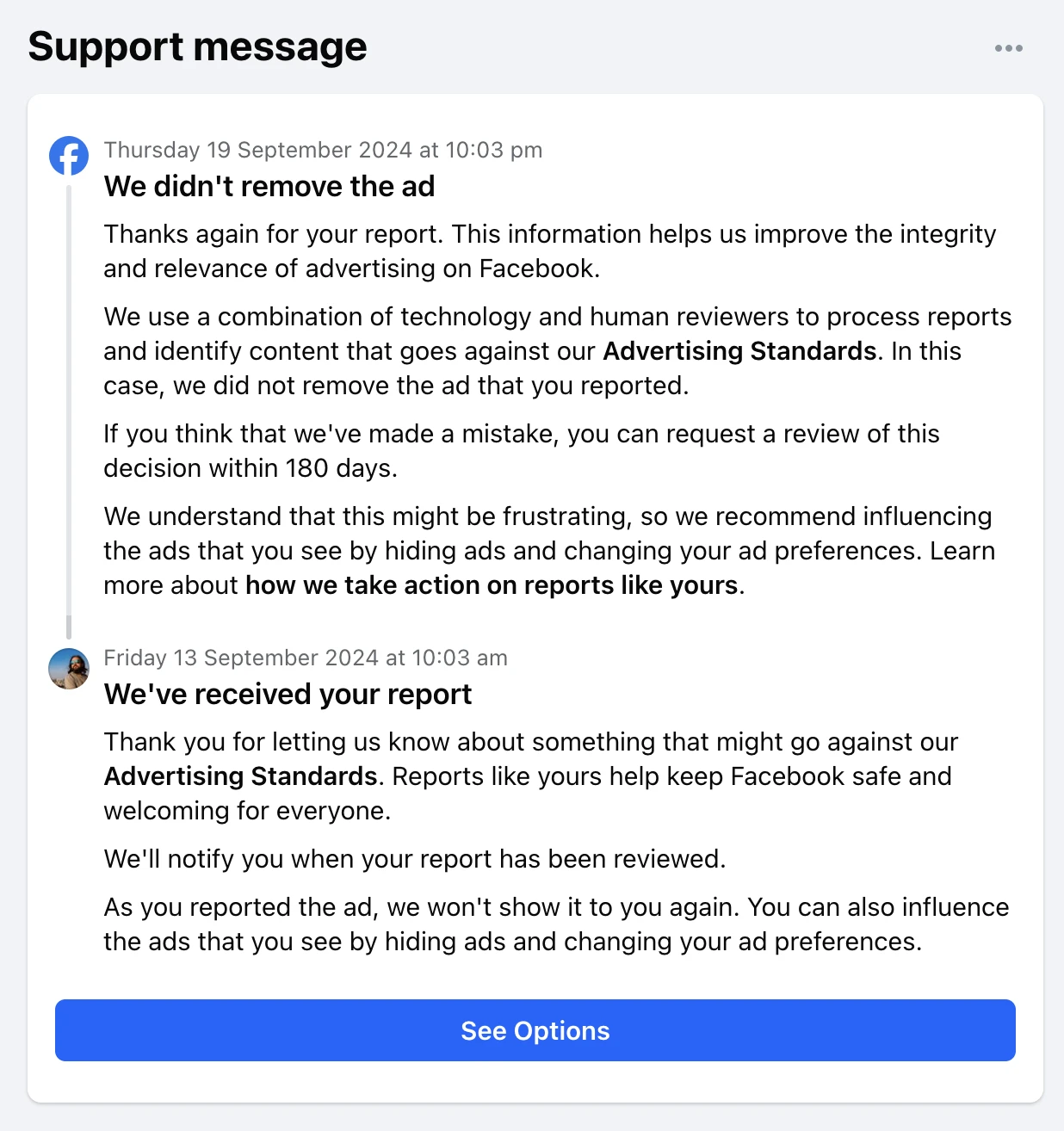
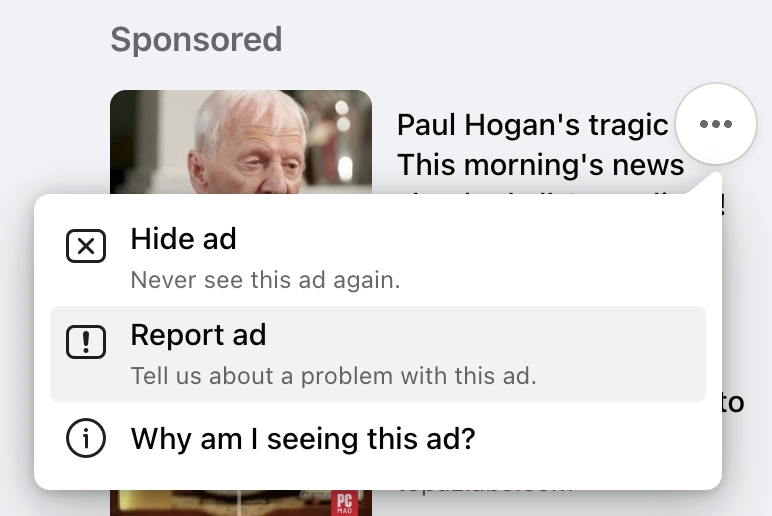
A scam advertisement on Facebook from early September 2024
I say these are obvious scams but here is a detailed example so you can judge for yourself.
Take a look at this typical ad that Facebook showed me in early September. The ad has all the hallmarks of this
particular scam:
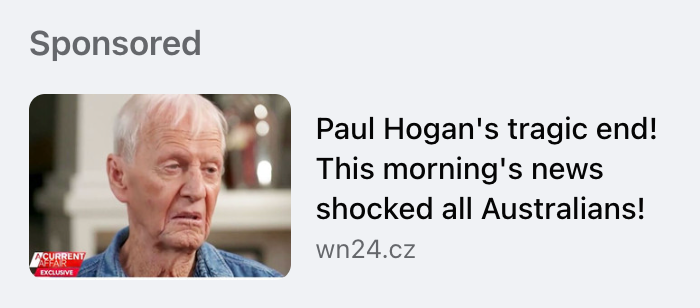
Mentions a famous Australian, in this case Paul Hogan.
Implies that they are either dead or in trouble:“Paul Hogan’s tragic end!”
Pretends to be a legitimate news website though often the URL doesn’t make sense or match the image, like Czech
website wn24.cz here for an Australian celebrity.
This pattern is so common and so consistent it should immediately raise red flags. It isn’t proven to be a scam at this
point… but every ad like this that I’ve looked into turns out to be a scam. I’m sure you’ll see the pattern yourself
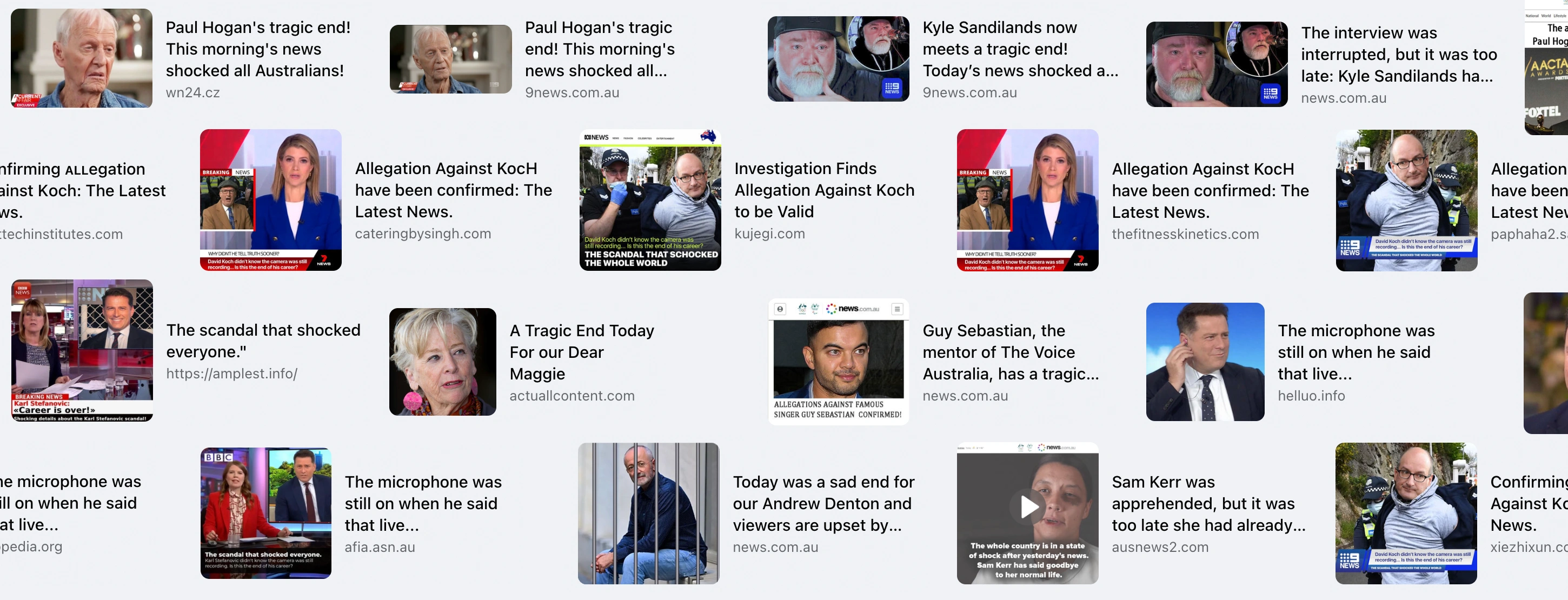
after just a few ads. Here’s a selection of the hundreds of scam ads I’ve seen on Facebook in the last few years to
demonstrate:
A composite image of some scam ads I've seen on Facebook in the last few years
They’re not using exactly the same text and images, but they are similar enough that I reckon a human reviewer should
immediately recognise ads that fit this pattern.
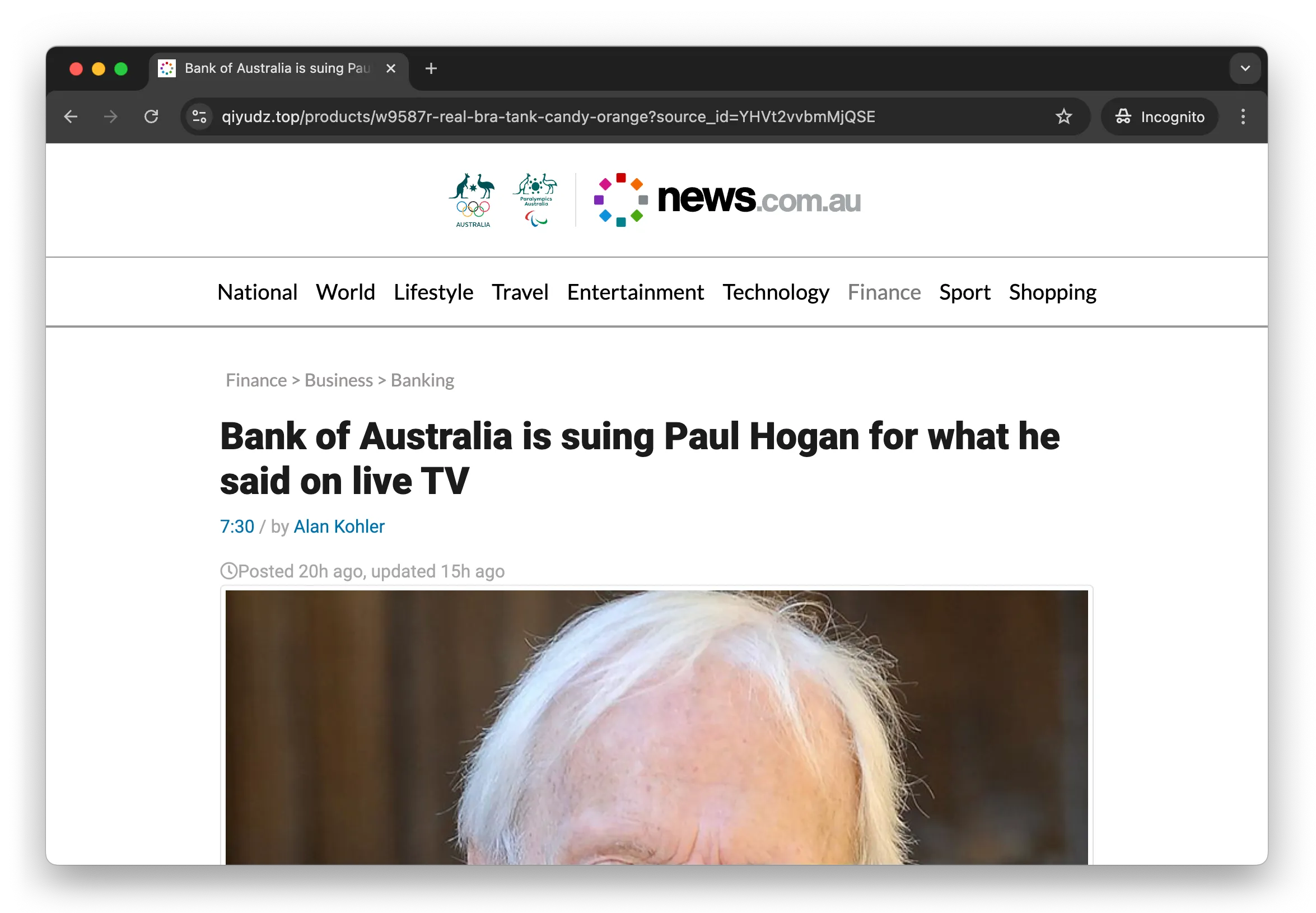
Clicking on any of those advertisements would take me a fake news article about the celebrity pictured in the ad. For
this Paul Hogan ad it is a fake news.com.au website with a headline “Bank of Australia is suing Paul Hogan for what he
said on live TV” which looks like this:
The scam website linked to from the Facebook ad above.
This is not a legimate news article. The easiest way to determine that is by the URL on the address bar:
Uses an obscure domain: qiyudz.top instead of news.com.au
The domain doesn’t match the one shown on the ad: this is qiyudz.top but the ad showed wn24.cz
The slug doesn’t relate to the story:‘real-bra-tank-candy-orange’ clearly isn’t referring to a news story
Those are basic checks which anyone could do even if they’re not Australian and don’t know who Paul Hogan is. That
should be sufficient evidence that this is a fake news story, but someone with a little knowledge and a little time to
do some more checks would find several more problems:
Wrong design: this doesn’t look like the legitimate news.com.au site
Links don’t work: clicking the National, World, Lifestyle etc links doesn’t do anything
No advertising: real news sites are desperate for money so they cover their pages in ads
Non-existent bank: there is no such thing as the ‘Bank of Australia’
Unlikely author: Alan Kohler and 7.30 appear on ABC, which is a competitor to news.com.au
Undated article: says ‘Posted 20h ago’ rather than the actual date, and that ‘20h ago’ never changes
At this point we’ve established that this is not a legitimate news article but we have not yet confirmed that it is a
scam. The evidence that this is a scam is in the text of the article. It’s a very long page so I haven’t included
everything here but you may view the entire page in these screenshots:
Fake news stories or ads that claim a celebrity recommends this scheme to make big money.
Emails, websites or ads with testimonials and over-the-top promises of big returns.
High pressure tactics designed to rush you to act so you don’t ‘miss out’.
We’ve already established that this is a fake news story about a celebrity with a fake ad, so that’s the first warning
sign.
The second warning sign is the over-the-top promise of big returns. The fake story makes several claims of unrealistic
returns, for example:
Paul Hogan: If you don’t believe me, I’ll prove it to you. Give me 375 A$, and with the help of X, I’ll earn you a
million in less than six months!
where X is the name of the scam product, and:
Paul Hogan: Try to imagine how much money will be in your balance in 2 weeks. If you invest at least 375 $ right now,
then in just 2 weeks, you will have tens of thousands!
For legitimate investment products a good investment might earn you between 5–10% per annum. This scam is promising
between 1600–12000% per annum which is completely unrealistic.
The over-the-top claims continue in the testimonials below. These testimonials are made to look like Facebook comments
but a quick check of the HTML shows that they have not come from Facebook and are unlikely to be genuine.
The third warning sign are the high pressure tactics. The page attributes this fake quote to Hogan:
I’m not sure how long it will remain free. I’ve heard that registration on the platform will become paid after a few
days, so I recommend hurrying. I hope you’ll be able to use the platform before it becomes paid or registration closes
for new users.
Then the signup form below says:
Registration will be free until the end of X
where X is always tomorrow’s date. No matter when you look at the site the date is always tomorrow.
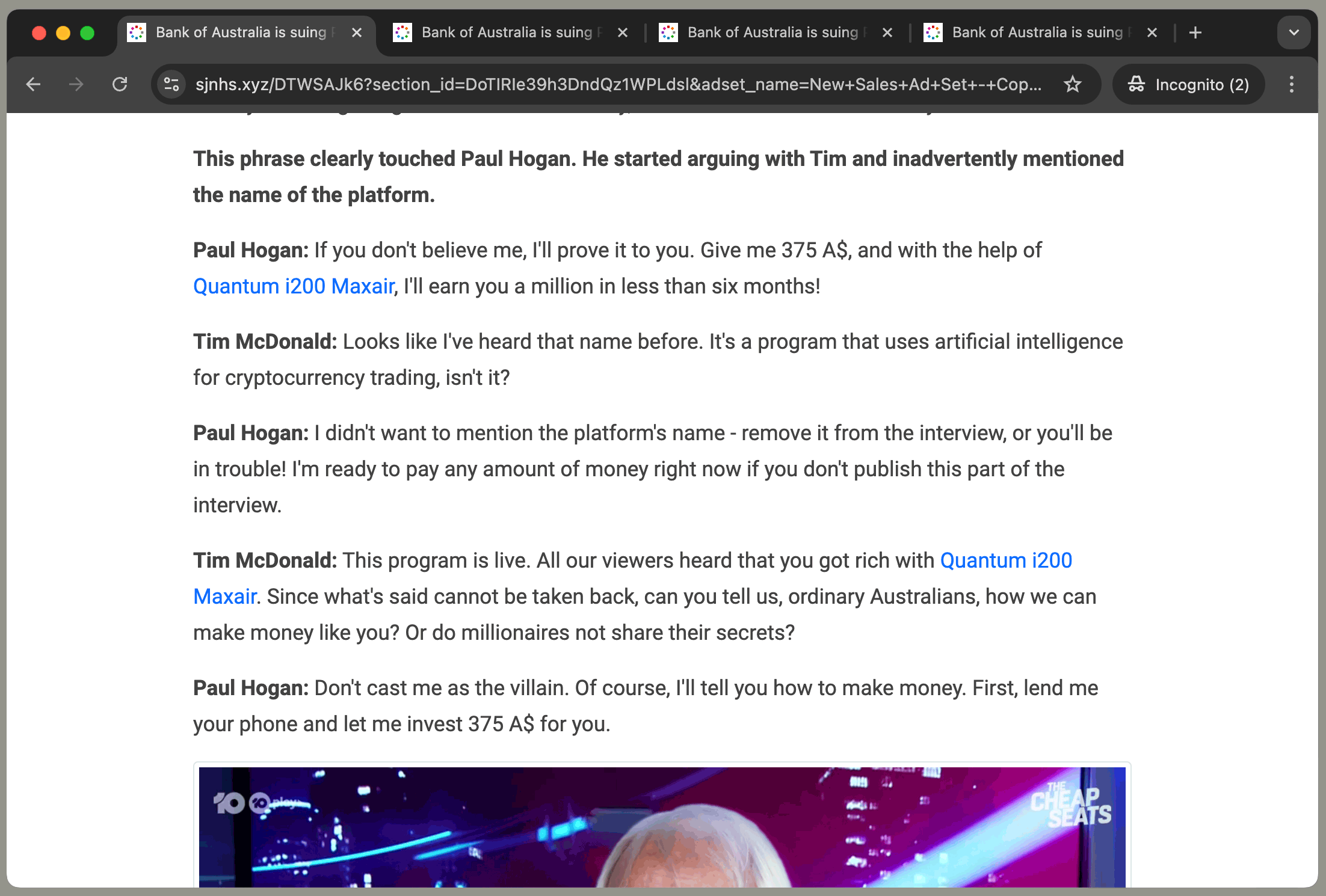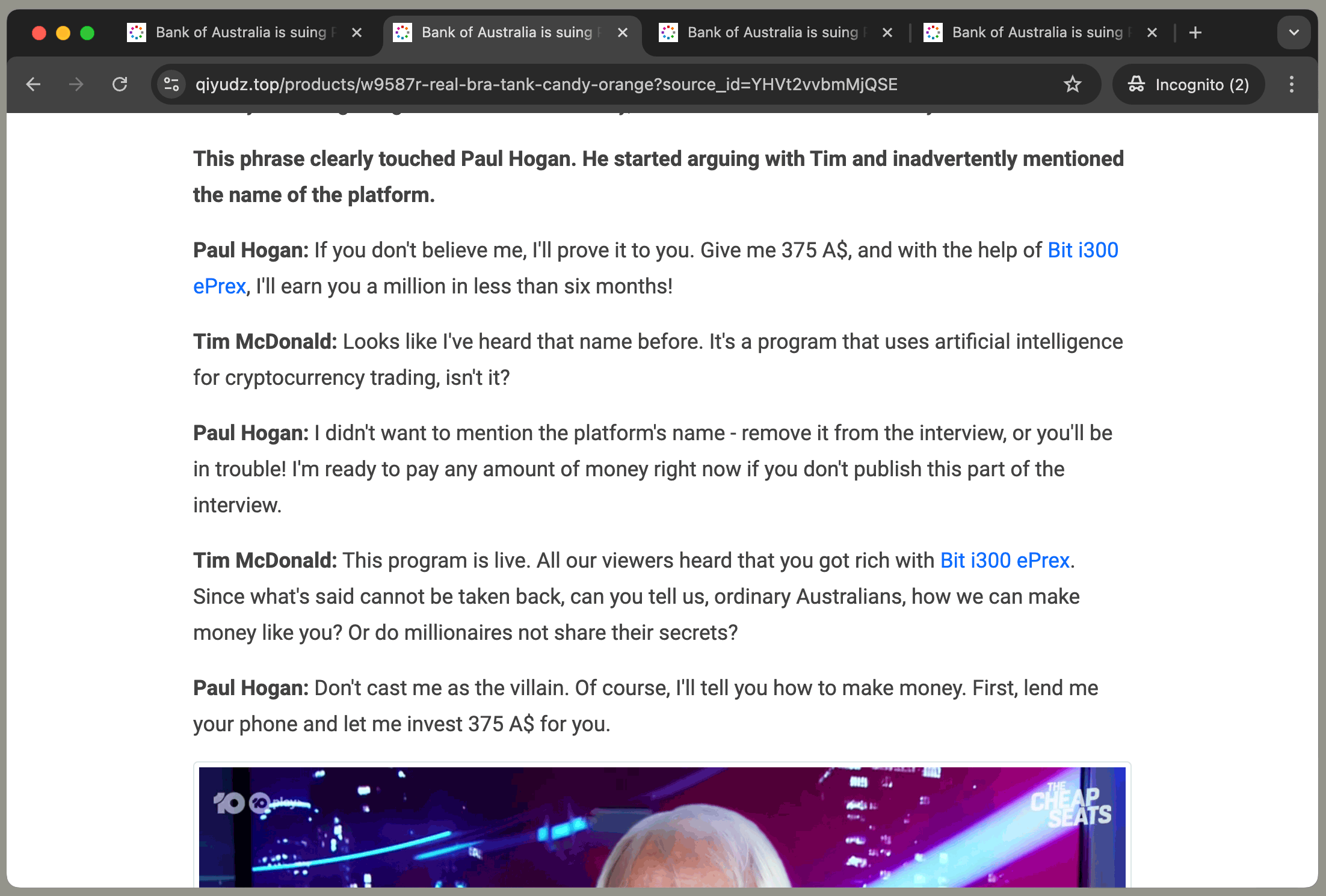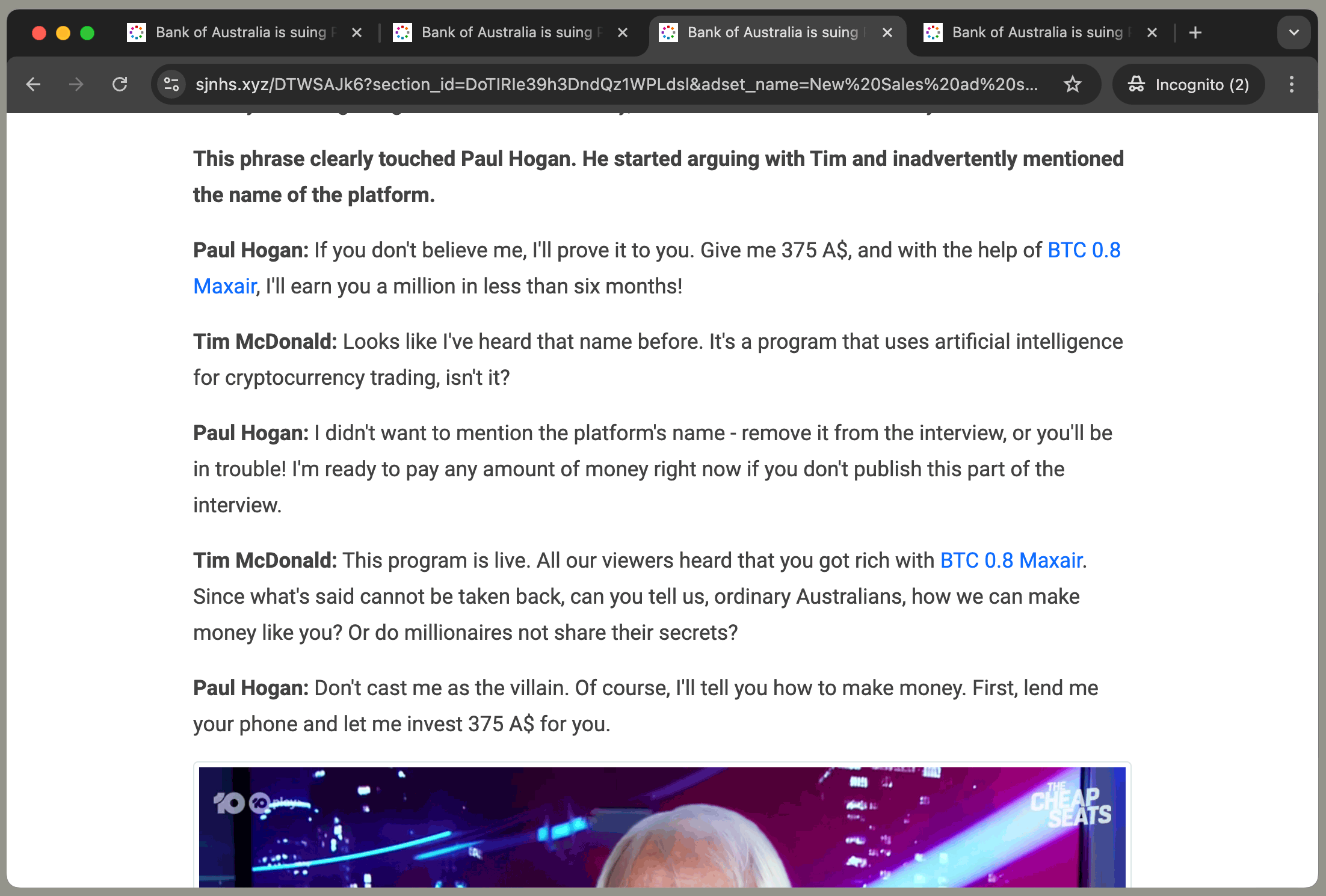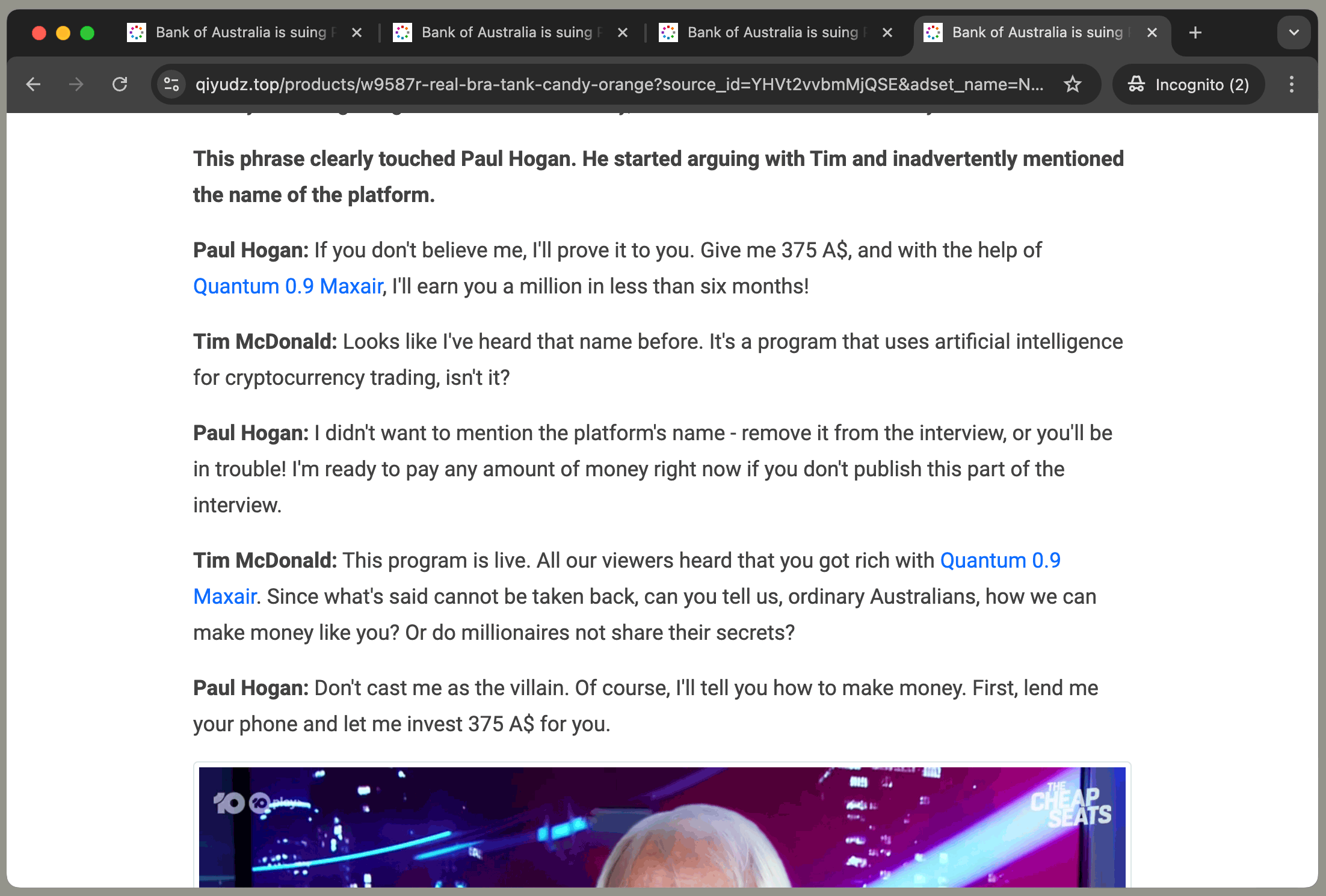
There is a final warning sign that ScamWatch doesn’t mention: when looking at several ads the product name quoted on the
article keeps changing. I clicked on four different ads in a space of a few minutes and got four completely different
product names in exactly the same article:
Each ad has the same article with a different product name: 'Quantum i200 Maxair', 'Bit i300 ePrex', 'BTC 0.8 Maxair', or 'Quantum 0.9 Maxair'
Even if you think this was a genuine transcript of a real conversation with Paul Hogan (which you shouldn’t!) then why
would he have had exactly the same conversation four times with just the product name changed? Of course he would not
have… the conversation must be fake.
Unacceptable business practices: Ads must not promote products, services, schemes or offers using identified deceptive or misleading practices, including those meant to scam people out of money or personal information.
Circumventing Systems: Ads must not use tactics that are intended to circumvent our ad review process. This includes techniques that attempt to disguise the ad’s content or destination (landing) page.
I reckon I’ve already established that the ad breaches those first two parts.
The third part I haven’t yet mentioned but is also in breach here. The ad mostly takes me to the fake story, but in
certain circumstances it will disguise it. For example if I use a VPN to make it look like I’m in the USA or if I
manipulate the URL to remove some parameters the ad will instead take me to a real news website—actually 9news.com.au
rather than news.com.au, but the point here is that it shows me a real news site rather than a scam site. This is likely
a technique used by the scammers to make it harder for Facebook to detect the scam. This circumvention means that
perhaps Facebook can’t see this breach of their rule… but I can, so I report it.
Facebook provides a link on the ad to allow me to report it:
After reporting this ad I didn’t hear anything for a week. Then one week later—exactly one week, down to the minute—I
received the response “We didn’t remove the ad”. That they rejected the report exactly one week later despite it being
so obviously a scam makes me highly suspicious that no-one looked at my report and so an automated response was
generated instead. The response says “We use a combination of technology and human reviewers to process reports” so
perhaps in some cases a human reviewer looks at the report… but in this case I suspect they did not.
One could argue that I don’t need to do anything. It’s not like I’m the only person to notice these scam ads. ABC have
been covering this problem for years in articles such as “Fake celebrity scam ads hijack Facebook accounts to target
Australians” and Media Watch’s coverage of Facebook scams. Media Watch had the same problem as me:
they reported a scam ad and were told “it does not go against our Ad Policies” despite it being an obvious scam.
And that was five years ago!
Australian businessman Andrew Forrest has been depicted in similar scam ads and so has taken Meta to court over them.
If he can successfully demonstrate Facebook has been negligent in publishing these scam ads then perhaps that will
finally cause Facebook to stop the ads. The case hasn’t yet reached trial though.
But it feels wrong wait and to do nothing; it has been five or six years now so it feels like I’ve ignored the scam for
too long. Meta hasn’t stopped it so it is up to us to do it instead. Writing this blog post is a small start for me.
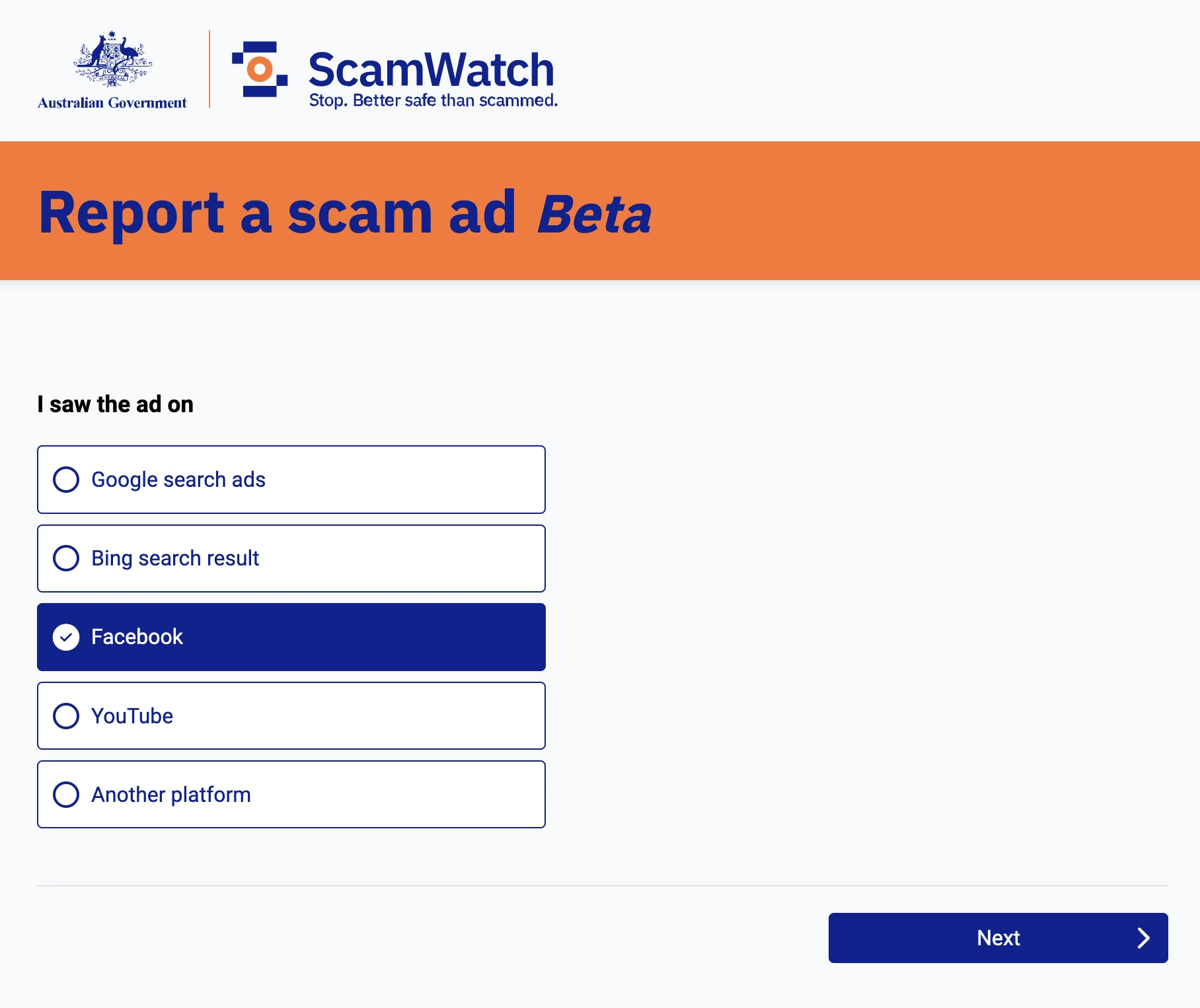
I have also taken to reporting the scam ads to the Australian Government’s new ScamWatch Report a scam ad
website. I don’t know what action the Government will be taking but I hope they can rectify Facebook’s failure
to take action on my scam reports.
Finally, I intend to request a review of this decision from Facebook to give them another chance to take responsibility.
If possible I will provide the URL of this blog post so that they can see detailed evidence of the scam. I’ll follow up
with another blog post on their response…

{kind=link}
{kind=link}